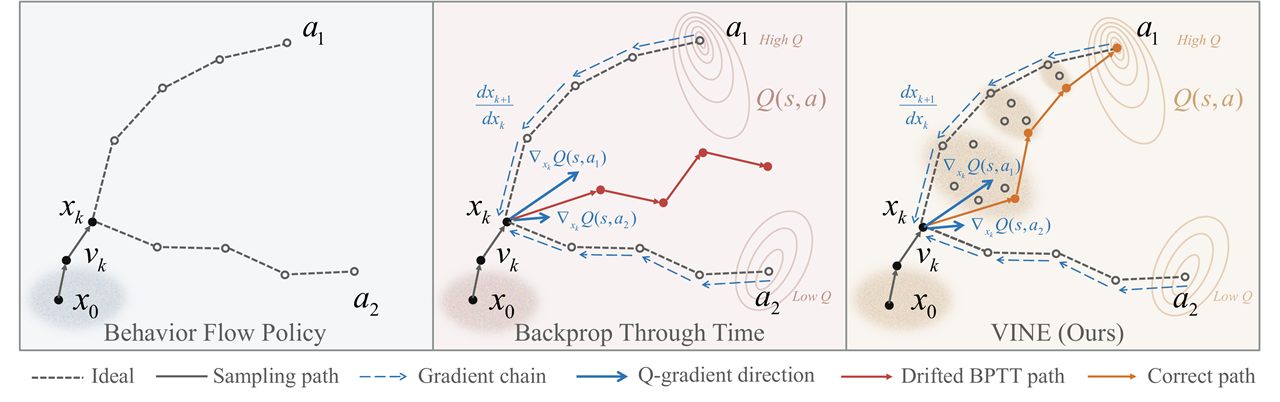
VINE: Taming Generative Control Policies for Reinforcement Learning
An RL-oriented sampling method that re-anchors the interpolation state at every denoising step, enabling stable end-to-end value-gradient optimization of flow-matching policies.



{kind=link}
{kind=link}